RogueDB Throughput: Effects of Batching

Introduction
RogueDB has two pillars that contribute directly to its performance: network communication server (eg. gRPC) and internal database implementation. Effective analysis of identifying bottlenecks for RogueDB requires analyzing the individual pillars in addition to the whole package. A deep dive into specific components better reveals localized bottlenecks without the noise of the entire application.
In this blog, we cover key benchmarks run on local systems that cut out the gRPC server. The focus resides primarily on the theoretical performance when network transmission and serialization are ignored. These benchmarks focus primarily on singular vs. batch message loads and identifies theoretical optimal batch sizes.
Setup
For this benchmark, calls are made directly to the scheduling mechanisms in RogueDB. The benchmark is run on local hardware, specifically an XPS 17 Intel i7-13700H with 32GB of RAM. Code for the benchmarks matches our gRPC profiling setups and YSCB General Purpose Benchmark, but the code is not shown in this article or the public GitHub repo to preserve proprietary implementation details. The benchmark compares single vs. batch performance when using a single thread.
Throughput Results
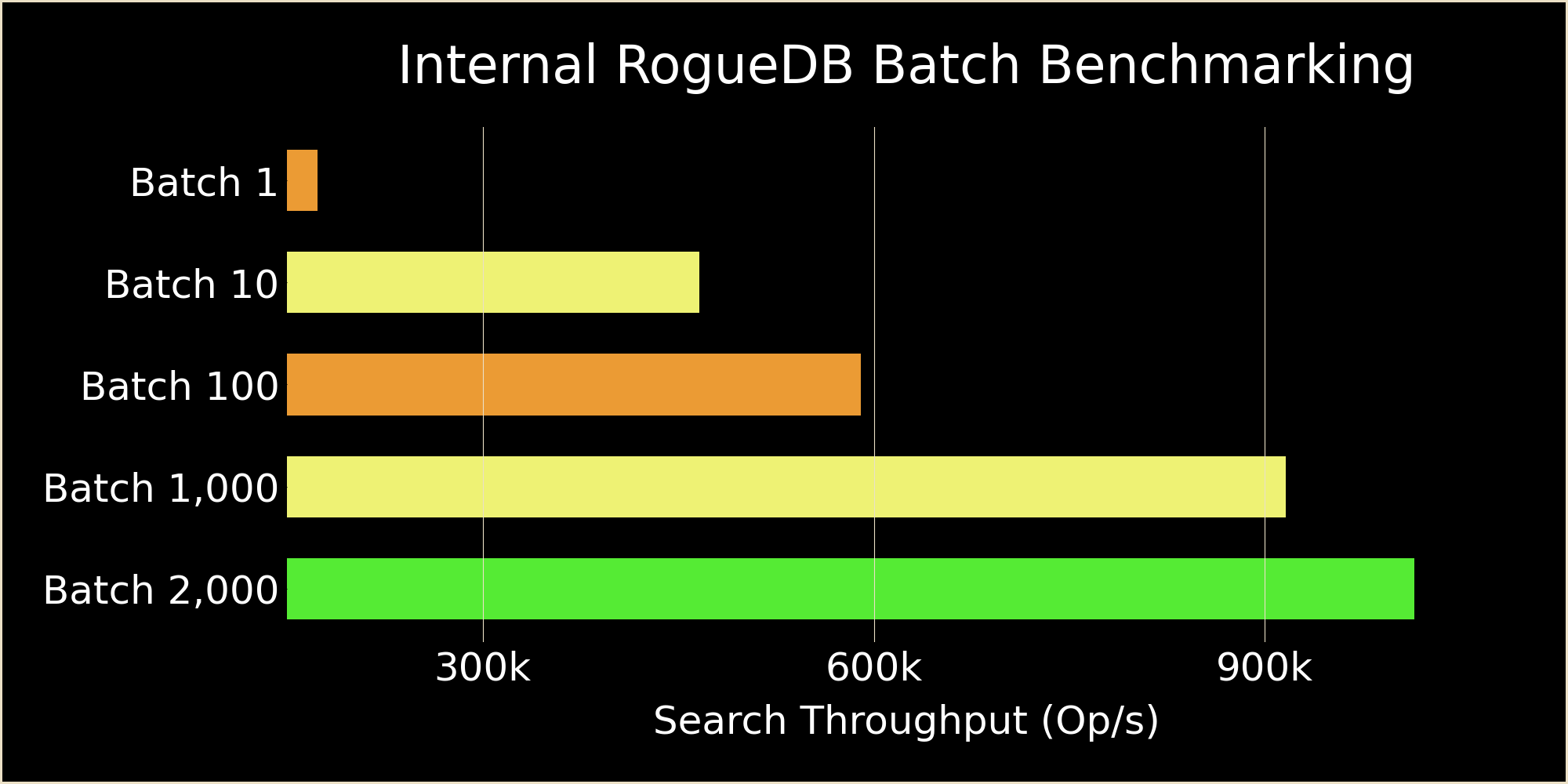
The benchmark resulted in the following for Search operations:
- Batch 1: 173,065 op/s
- Batch 10: 466,203 op/s
- Batch 100: 590,052 op/s
- Batch 1,000: 916,034 op/s
- Batch 2,000: 1,014,414 op/s
The benchmark resulted in the following for Write operations:
- Batch 1: ~23,000 op/s (extremely high variance, excluded in visual)
- Batch 1,000: 3,605,522 op/s
- Batch 2,000: 5,333,167 op/s
- Batch 5,000: 7,133,333 op/s
- Batch 10,000: 7,969,833 op/s
- Batch 20,000: 9,153,414 op/s
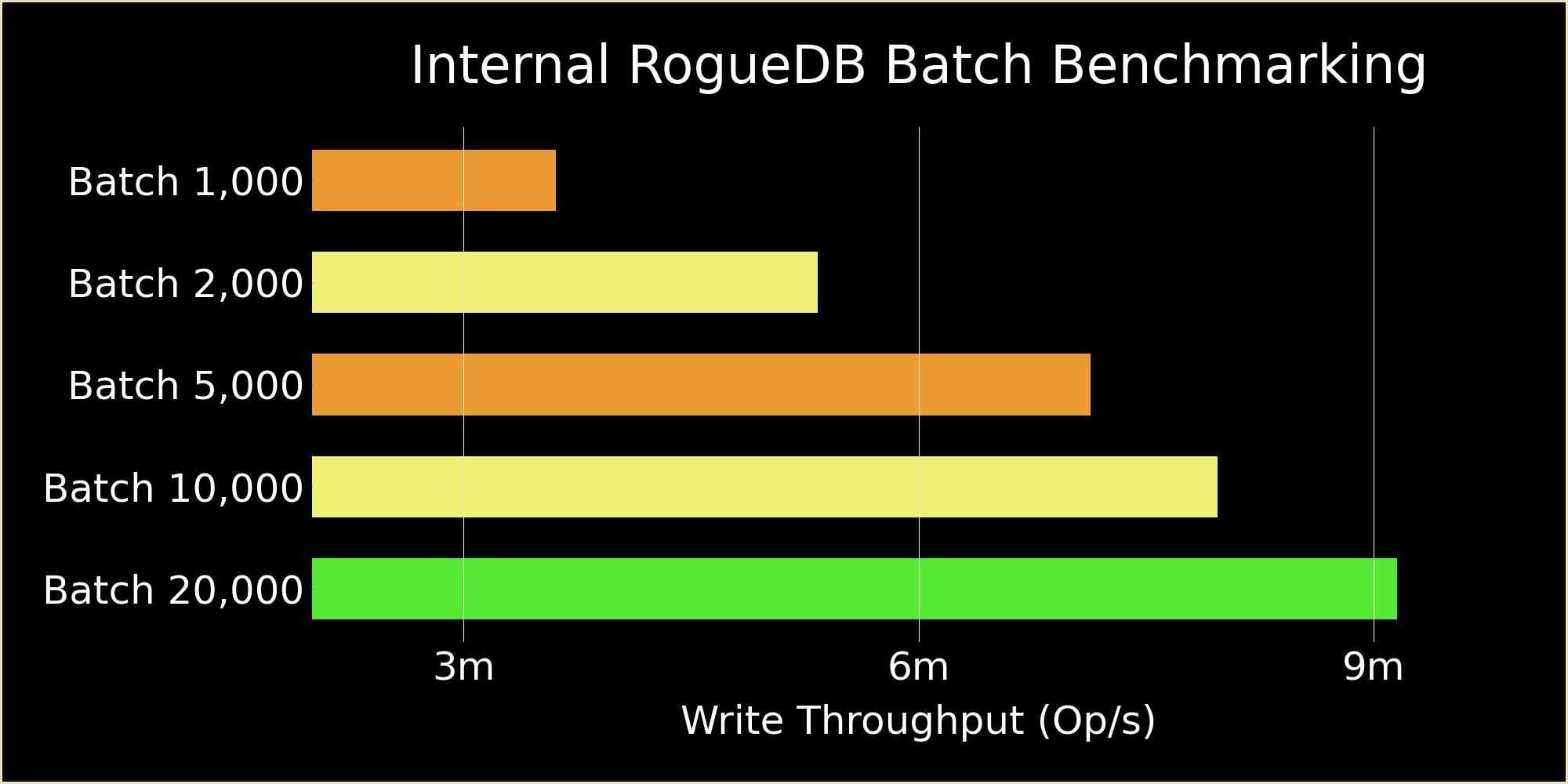
There is a clear and distinct performance improvement when using batching for scheduling work. For Search operations, this equates to a 5.8x performance improvement in this benchmark, and equates to almost a 400x performance improvement in Write operations. This directly drove the design decision for bidirectional streaming of theCRUD APIs to enable staging work for the scheduler in batches. Total throughput remains the most important feature of RogueDB when designing the underlying software architecture.
Discussion
Due to the drastic differences in performance, the decision to shift from a purely 1 to 1 equivalence of built-in native data structures was made. A light wrapper on the creation of a bidirectional stream by the client restores this ideal functionality. A future effort by RogueDB may include publishing very light client side wrappers to enable this without additional effort from customers.
While this drastically increases throughput, a small and negligible impact to latency (in relation to network latency) gets introduced as overhead per message due to the nature of batching. The floor of the best case latency gets shifted up by less than a microsecond. Future benchmarks will specifically target the measure of latency, but the associated code to execute is not massive by any means. The orders of magnitude improvement far outweigh a very small percentile increase in overall latency.
The design improves response latency significantly beyond network latency versus a design not utilizing batching for high saturation workloads. Additional total throughput enabled by batching allows for workloads that exceed throughput of a non-batching design due to no throttling from internal implementation saturation. Put simply: more work done faster means less waiting for work to start. More demanding workloads can therefore be done on less compute resources in a reliable manner without introducing undesirable latency from queueing.
RogueDB will undergo similar tuning as the new query categories become available (complex and compositional) to ensure consistent results. Further tuning based on non-indexed searches are expected with these changes. Currently, the optimizations for indexed search operations are applied naively to non-indexed search operations. Non-indexed search operations are by their very nature more compute intensive given the inability to use indexed to reduce the search space.
Conclusion
The trade-off of batching follows the same design philosophy used throughout the design of RogueDB: maximizing throughput inherently reduces latency for high throughput workloads. We do this by batching work to the underlying scheduling system to reduce demand on synchronization primitives. Due to the order of magnitude improvement, the design decision to diverge from an API that matches built-in data structures was made by swapping to a bidirectional streaming API.
