gRPC Throughput: Communication Patterns

Introduction
Transmission of data over the network in an efficient manner reduces costs and increases performance. In particular, applications want to maximize utilization of available bandwidth and compute resources. There are two key pillars of RogueDB as a SaaS database: database implementation and communication server. To maximize throughput and reduce latency, effective usage through profiling and tuning gRPC are required with high impacts to performance if neglected.
Communication falls roughly into three buckets:
- Alternate Send and Receive
- Send All then Receive All
- Send All with No Response
A reasonable assumption suggests the performance of these three patterns are equivalent. Bidirectional streaming with thread-safe reads and writes (eg. receive and send) ought to not impact each other. Rather than assuming this to be the case, the team at RogueDB profiled the three communication patterns to understand the performance in practice. The benchmark's objective intends to identify any major relative differences in throughput, irrespective of message contents and underlying compute. Simply put: Are there any differences in the theoretical maximum throughput of each communication pattern?
Setup
For this benchmark, all RPCs are bidirectional streams to emulate the performance sensitive CRUD APIs of RogueDB. The Search and Response message populates the writes and reads to the server. Both client and server perform the absolute minimal steps to replicate the desired communication patterns. For the full code, see our public GitHub repo.
Throughput Results
The benchmark resulted in the following:
- Alternate Send and Receive: 9,960 op/s
- Send All then Receive All: 34,197 op/s
- Send All with No Response: 71,489 op/s
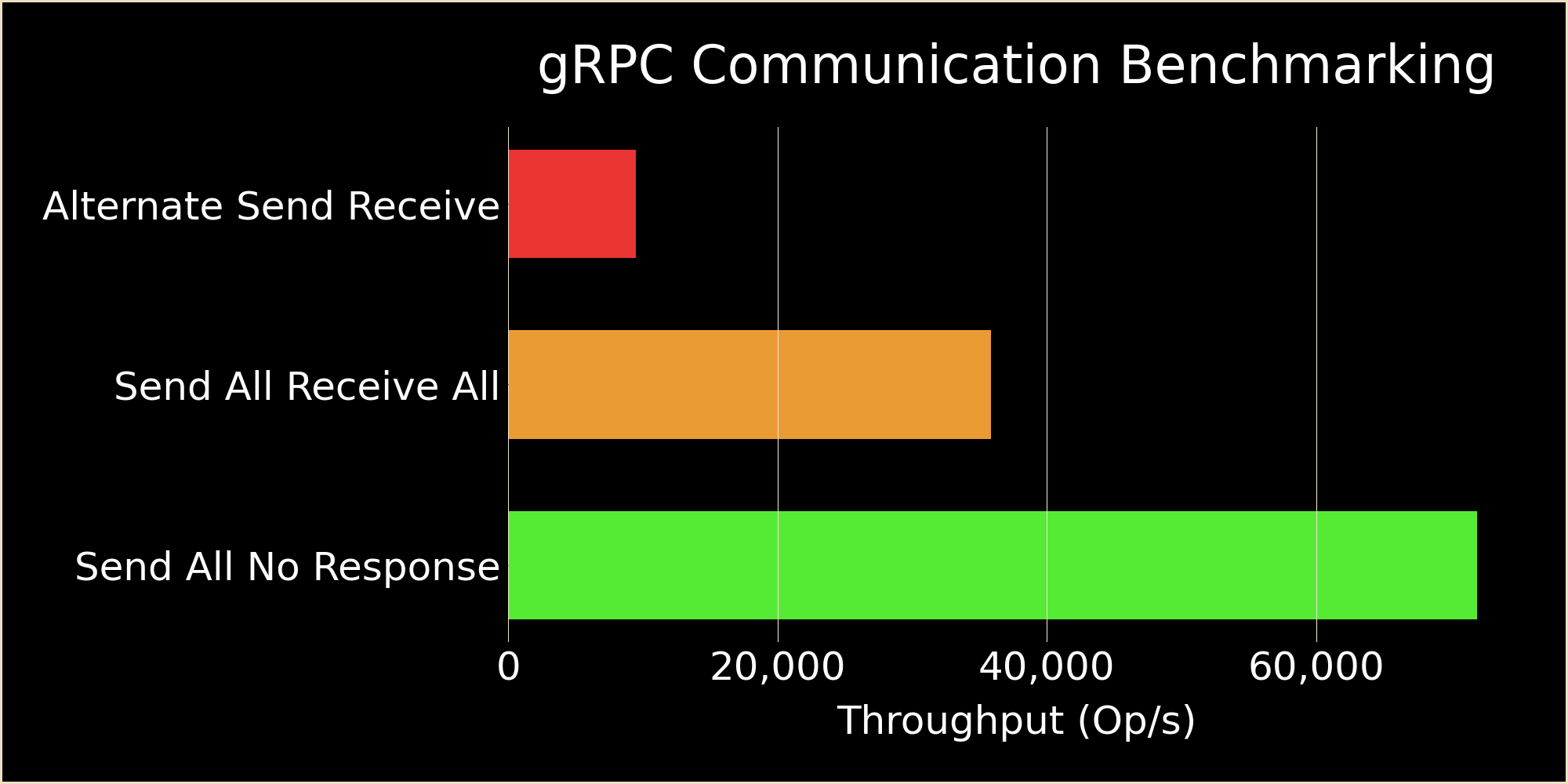
Send All then Receive All and Send All with No Response achieve a 3.4x and 7.1x improvement over Alternate Send and Receive. Significant improvement can be obtained by doing send and receive communication in continuous batches of one or the other. Elimination of receive communication entirely represents the ideal scenario.
Discussion
The differences in performance between Send All then Receive All with Send All with No Response is straightforward. Total number of messages reduces by half given no responses. Any additional differences likely derives from noise and underlying low-level implementation details of gRPC.
The surprising result between Alternate Send and Receive with Send All then Receive All does not match with intuition. While the RogueDB team has spent time diving into gRPC's implementation details, full understanding of a library of such massive size poses significant technical challenges. We stripped the library to only the C++ related code only to be left with hundreds of remaining files spanning across dozens of directory structures. Unfortunately, a significant amount of abstraction in the implementation details prevent easy consumption and following of the minute details required to fully understand bottlenecks in performance due to several points of indirection. However, there are a number of reasonable assumptions that can be drawn based on experience and educated guesses.
The bidirectional streaming notates itself as thread safe for concurrent read and write operations. This indicates separate threads dedicated to each stream given asynchronous code could not be found from our investigation. Introduction of multiple long running threads require a degree of synchronization when errors arise in either operation to terminate the streams. These errors can arise on either the client's side or server's side. Dependency of one stream to be in a good state (eg. no non-OK gRPC Status) matches usage of the library as a termination from a Read() or Write() invalidates both from future use. Overhead and contention from reads and writes occurring at the same time are highly likely with the additional overhead of checking the health of the other stream.
RogueDB's team does not make any claims on network communication expertise. Our focus remains entirely on database implementation at the time of this writing. Regardless, we suspect there to be at least some overhead as it relates to network communication when traffic flows in both directions at once, but this could be an incorrect assumption.
Conclusion
gRPC performs best when there are not concurrent reads and writes on a bidrectional stream by a factor of 3.4x in benchmarking. These findings guided development of RogueDB's API as it relates to design and execution.
For the Create, Update, and Remove APIs, we leverage the gRPC Status sent for preemptive termination and successful execution of a stream on closure. This pattern leverages a pre-existing pattern for communication and reduces total network traffic. Total throughput increased by a factor of ~3.5x. Further increases bottleneck due to checks server side to ensure stable operation such as managing RAM utilization, determining the message sent, and routing messages accordingly.
The Search API utilizes batching of results in the Response message as a middle ground of Alternate Send and Receive with the Send All Receive All. Total throughput increased by~3.5x mark during development efforts. The bottleneck shifts back to the database and server implementation.
RogueDB's team continues to experiment with server and database design and implementation details. Ideally, network bandwidth becomes the sole limitation factor of throughput. Internal benchmarks on local 8-core systems producing and consuming data have performance around 1.75 million messages per second or .875 GB/s of throughput for a single message. The RogueDB team strives to enable saturation of the 10 GB/s network limit on Google Compute VMs for multi-message processing.
