gRPC Throughput: Effects of Batching

Introduction
All traffic sent over a network has a minimum amount of overhead related to source, destination, and additional metadata dependent on the specific network protocol. Network transmission costs can be substantial in applications requiring frequent access to services in cloud based systems both in terms of monetarily and performance. Maximizing the efficiency of network traffic sent over the wire becomes critical to achieve maximal throughput with RogueDB while reducing the impact of non-negotiable metadata on costs over time.
There are effectively two methods of sending network traffic:
- One message per load
- Batching multiple message per load
The following benchmark demonstrates an often underestimated impact of performance when opting for single message loads versus batch loads. To achieve reasonable increases in performance, the required batch size amounts to relatively low numbers. Benefits of multiple messages per load in terms of reducing are non-negotiable metadata overhead are linear where each message added to a load reduces overall bytes sent by that non-negotiable metadata size. Our objective focuses on throughput: What are the relative differences in throughput performance when varying the number of messages per load?
Setup
For this benchmark, we use bidrectional streams that match RogueDB's CRUD APIs. The Search and Response message populates the writes and reads to the server. Both client and server perform the absolute minimal steps to increase messages per load utilizing an alternating send and receive communication pattern. The benchmark was ran on a single machine (via localhost), specifically the XPS 17 Intel i7-13700H with 32GB of RAM, rather than between two machines over a full-fledged network. For the full code, see our public GitHub repo.
Throughput Results
The benchmark resulted in the following:
- Batch Size of 1: 9,482 op/s
- Batch Size of 10: 85,479 op/s
- Batch Size of 100: 622,246 op/s
- Batch Size of 1,000: 1,939,291 op/s
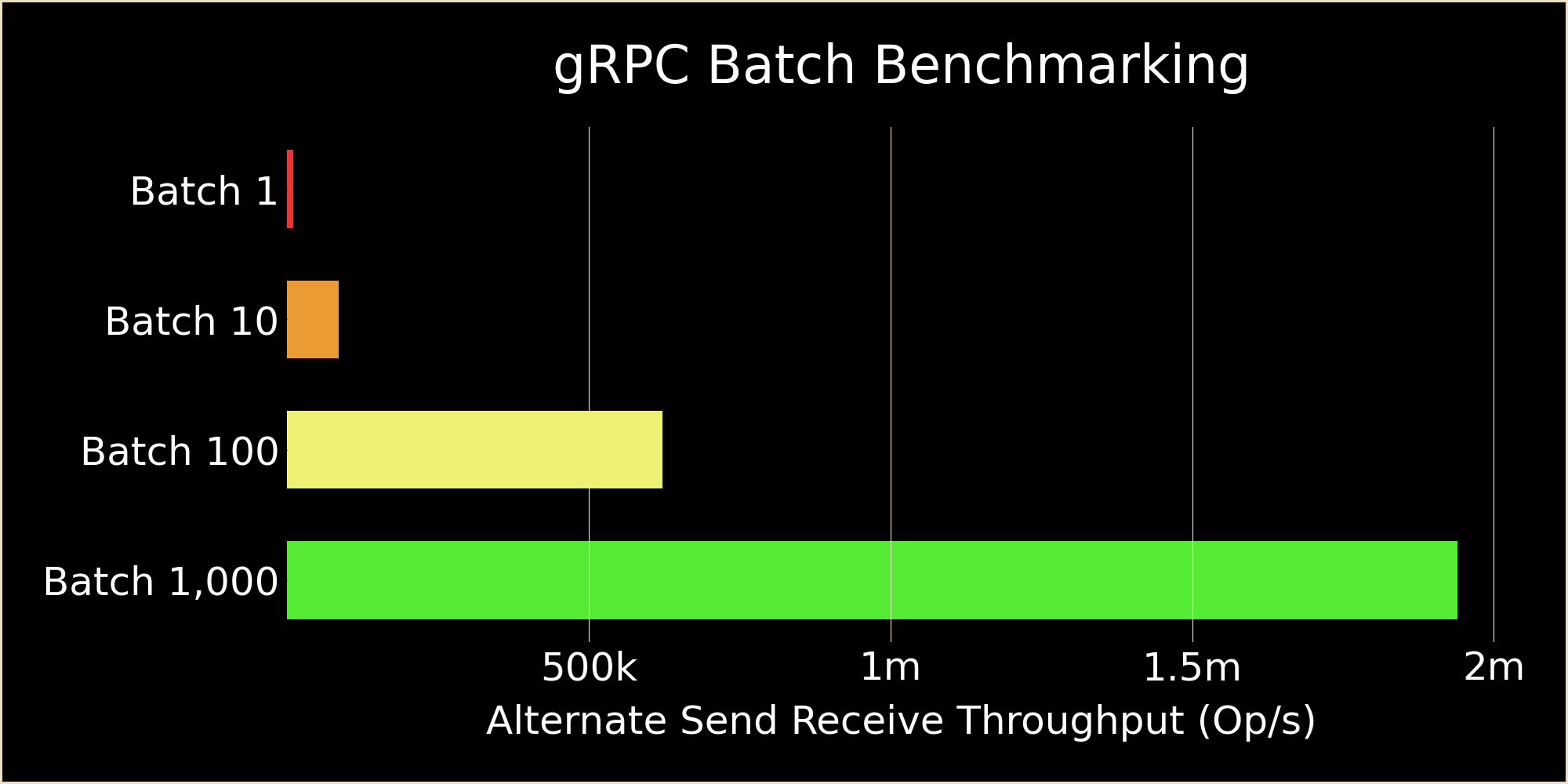
From a single message load to 10, 100, and 1,000 message loads total throughput increases by 9x, 65x, and 204x respectively. The increase in throughput is not linear with diminishing returns as the batch size grows larger where the last jump from 100 to 1,000 (10x increase) only resulted in an additional ~3x increase. Initial increases are about 90% efficient from 1 to 10 demonstrating out-sized impacts for very small batch sizes.
Discussion
Causation can be directly tied to the overhead of network communications, primarily the round-trip transfer cost. These benchmarks understate the effect due to using a local machine's localhost network loop-back (eg. minimal round-trip times). A true machine to machine network from local networks to continental spanning transmission have orders of magnitude higher round-trip times. Given batching's solution aims to reduce roundtrip costs by reducing total number of trips, there are diminishing returns proportional to non batch trips divided by batch trips (eg. excluding serialization costs, client logic costs, and server logic costs). The highest gains in throughput are therefore in smaller batch sizes, but gains from batching even a large number of messages are still significant even at larger batch sizes and worth it if latency is not a predominant issue.
Conclusion
Unless competing technical requirements exist for latency not tied to total throughput limitations, batching messages into a single load offers substantial performance gains. Not discussed here are the additional benefits of reducing load handling logic that is often complex with high overhead due to the multi-threaded nature of gRPC in this specific case. Even small batch sizes are meaningful to increased throughput performance by an order of magnitude that justify any potential overhead to facilitate.
RogueDB specifically optimized and designed for batch loads to increase total throughput due to the results of these benchmarks. More simply means more, not less, when batching messages for performance.
